Research:
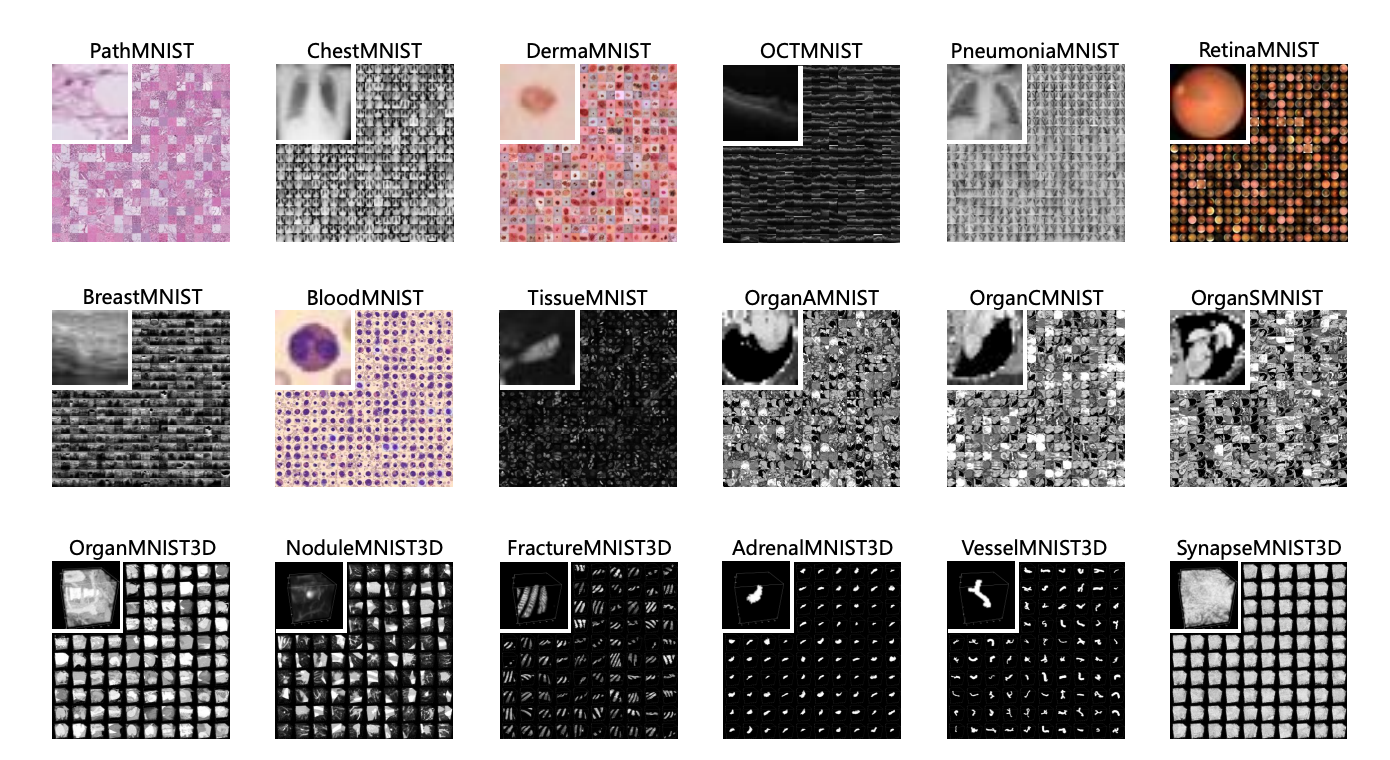
A large-scale MNIST-like dataset collection of standardized biomedical images, including 12 datasets for 2D and 6 datasets for 3D, was introduced by researchers from Shanghai Jiao Tong University, called MedMNIST v2. In order to perform classification on lightweight 2D and 3D images with different dataset scales (from 100 to 100,000) and varied tasks (binary/multi-class, ordinal regression, and multi-label), MedMNIST v2 was developed to cover primary data modalities in biomedical images. The final dataset, with a total of 708,069 2D photos and 9,998 3D images, might be used for a variety of research and instructional projects in biological image analysis, computer vision, and machine learning. For MedMNIST v2, they benchmarked a number of baseline techniques, including 2D and 3D neural networks and open-source and paid AutoML products. You can access the information and the source code here.
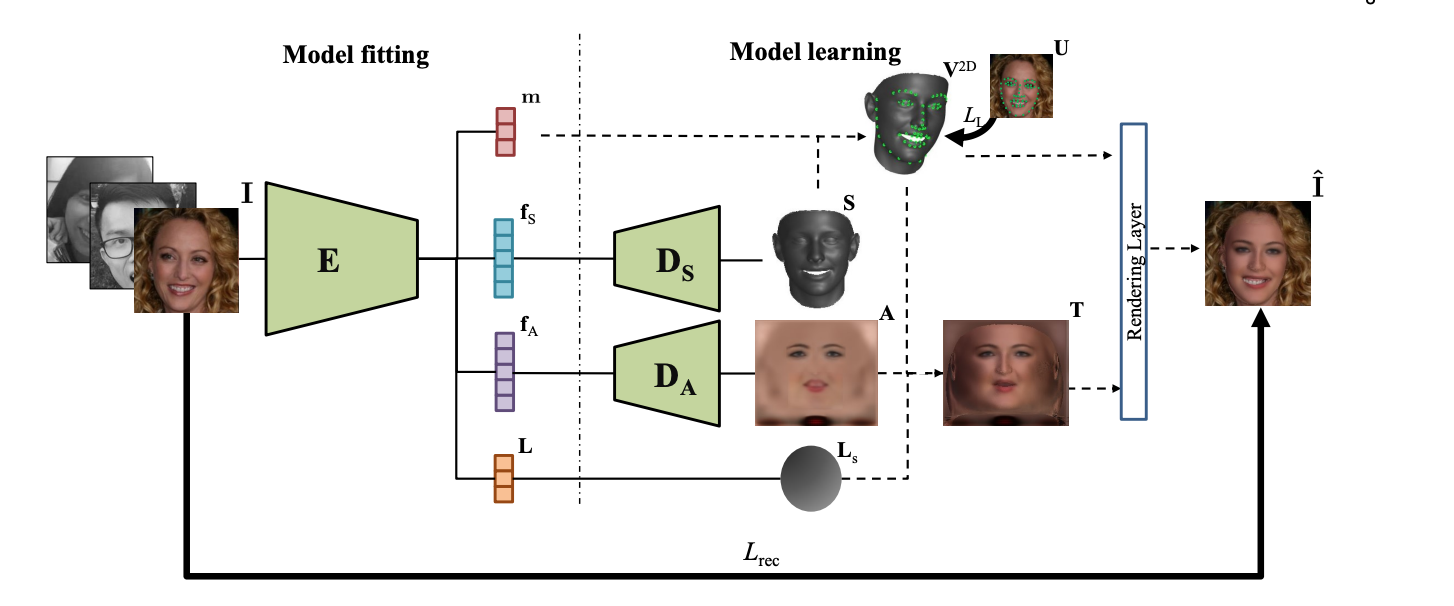
In facial analysis, such as model fitting and picture synthesis, the 3D Morphable Model (3DMM) is frequently employed as a traditional statistical model of 3D facial form and albedo. Two sets of PCA basis functions are used to represent the conventional 3DMM, which is learned from a collection of 3D face scans and accompanying well-controlled 2D face pictures. The representation power of 3DMM may be constrained by the type and volume of training data as well as the linear bases. To solve these issues, researchers from IEEE suggested a novel method for learning a nonlinear 3DMM model from a vast collection of real-world face photos without the need for 3D face scans. Visit their project page here to see the source code and additional findings.
Open Source News:

In order to be the first to open source a system similar to ChatGPT, a new team of researchers going by the name Together plan to solve the present challenges. Together unveiled OpenChatKit, a platform for building AI-powered chatbots with both specialized and general purposes, as its first significant project. The kit, which is accessible on GitHub, consists of trained models and an "extensible" retrieval system that enables the models to get data (such as the most recent sports scores) from numerous sources and websites.

The steps for establishing an open source program office have been released by GitHub as internal guidance and tools (OSPO). The new GitHub-OSPO repository on GitHub is designed for companies that are establishing their first OSPO and contains everything from regulations governing contributor license agreements (CLA) to instructions on archiving repositories. Basically, it all revolves around assisting fledgling open source initiatives in becoming something more significant and structured.